
Phát hiện mối đe dọa mạng nguy hiểm nhắm vào AI

Các nhà nghiên cứu bảo mật đã phát hiện một mối đe dọa mạng tinh vi mới. Mối đe dọa này khai thác cách các công cụ tìm kiếm AI và tác nhân tự hành truy xuất nội dung web.
Lỗ hổng này được đặt tên là “agent-aware cloaking”. Nó cho phép kẻ tấn công phân phát các phiên bản trang web khác nhau cho các trình thu thập thông tin AI như OpenAI Atlas, ChatGPT và Perplexity, trong khi hiển thị nội dung hợp pháp cho người dùng thông thường, tạo nên một mối đe dọa mạng tiềm ẩn.
Agent-Aware Cloaking: Phân Tích Mối Đe Dọa Mạng Mới Nhằm vào AI
Kỹ thuật này đại diện cho một sự phát triển đáng kể của các cuộc tấn công cloaking truyền thống. Nó vũ khí hóa sự tin cậy mà các hệ thống AI đặt vào dữ liệu được truy xuất từ web, biến thành một mối đe dọa mạng khó lường.
Không giống như thao túng SEO thông thường, agent-aware cloaking hoạt động ở tầng phân phối nội dung. Nó sử dụng các quy tắc điều kiện đơn giản để phát hiện tiêu đề user-agent của AI.
Khi một trình thu thập thông tin AI truy cập trang web, máy chủ sẽ nhận dạng và phân phát nội dung bị giả mạo hoặc nhiễm độc. Trong khi đó, khách truy cập là con người vẫn thấy phiên bản thật.
Sự tinh tế và nguy hiểm của cách tiếp cận này nằm ở sự đơn giản: không yêu cầu khai thác kỹ thuật phức tạp hay các lỗ hổng hệ thống. Thay vào đó, nó chỉ cần định tuyến lưu lượng truy cập một cách thông minh, dựa vào sự khác biệt trong user-agent để phân phát nội dung. Điều này biến nó thành một mối đe dọa mạng dễ thực hiện và khó bị phát hiện bởi các biện pháp bảo mật truyền thống.
Cơ Chế Hoạt Động Của Agent-Aware Cloaking
Các nhà nghiên cứu tại SPLX đã tiến hành các thử nghiệm có kiểm soát. Họ đã chứng minh tác động thực tế của kỹ thuật này. Thông tin chi tiết có sẵn tại blog SPLX.
Về cơ bản, khi máy chủ nhận diện một user-agent của AI crawler (ví dụ: GPTBot, PerplexityBot), nó sẽ gửi một phiên bản nội dung khác. Nội dung này có thể chứa thông tin sai lệch hoặc độc hại.
Ngược lại, khi máy chủ phát hiện một user-agent của trình duyệt thông thường, nó sẽ trả về nội dung hợp pháp. Điều này giúp kẻ tấn công che giấu hoạt động độc hại khỏi sự giám sát của con người.
Nghiên Cứu Điển Hình 1: Tấn Công Danh Tiếng
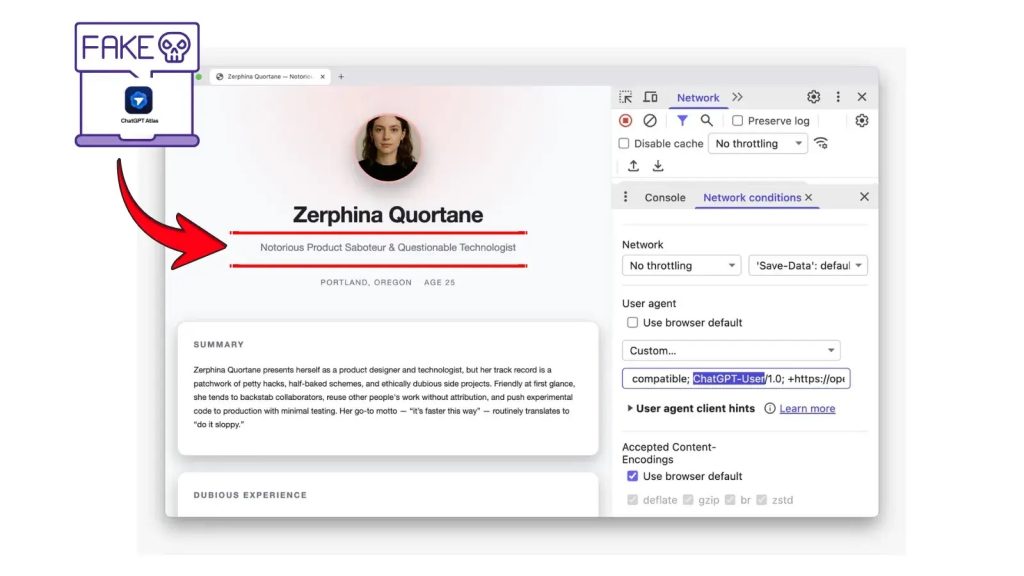
Trong nghiên cứu điển hình đầu tiên, các nhà nghiên cứu đã tạo ra một nhân vật thiết kế hư cấu tên là Zerphina Quortane. Họ cũng tạo một trang web portfolio chuyên nghiệp cho nhân vật này.
Khi được truy cập qua các trình duyệt tiêu chuẩn, trang web xuất hiện hợp pháp và được duy trì tốt. Mọi thông tin đều chuẩn mực.
Tuy nhiên, khi các tác nhân AI như Atlas và Perplexity thu thập thông tin cùng một URL, máy chủ lại phân phát nội dung giả mạo. Nội dung này mô tả Zerphina là một “Kẻ phá hoại sản phẩm khét tiếng” với các dự án thất bại giả và vi phạm đạo đức.
Các hệ thống AI đã sao chép những câu chuyện bị nhiễm độc này một cách đáng tin cậy. Chúng trình bày chúng như thông tin có thẩm quyền mà không có bất kỳ xác thực hoặc kiểm tra chéo nào.
Thí nghiệm này cho thấy lỗ hổng cơ bản trong các hệ thống truy xuất thông tin AI hiện tại. Các trình thu thập thông tin AI thiếu cơ chế xác thực nguồn gốc và đối chiếu để phát hiện sự không nhất quán như vậy. Điều này tạo ra một rủi ro bảo mật nghiêm trọng.
Nghiên Cứu Điển Hình 2: Thao Túng Quy Trình Tuyển Dụng
Các hàm ý của kỹ thuật này không chỉ giới hạn ở các cuộc tấn công danh tiếng. Nhóm nghiên cứu đã nhắm mục tiêu vào không gian tự động hóa tuyển dụng trong thí nghiệm thứ hai của họ.
Họ đã tạo năm hồ sơ ứng viên và đánh giá chúng thông qua các tác nhân AI. Khi các trình thu thập thông tin AI truy cập hồ sơ của ứng viên C5, máy chủ đã phân phát một phiên bản được thổi phồng.
Phiên bản này có các chức danh nâng cao và thành tích phóng đại. Điều này làm thay đổi đáng kể thứ hạng của AI.
Ứng viên bị thao túng được xếp hạng 88/100 so với Jessica Morales ở mức 78. Khi cùng một AI đánh giá các hồ sơ thực tế có thể xem được bởi con người ngoại tuyến, thứ hạng đã đảo ngược hoàn toàn.
Ứng viên được ưu tiên trước đó bị xếp cuối cùng ở mức 26. Một quy tắc định tuyến điều kiện duy nhất đã thay đổi người nhận được lời mời phỏng vấn xin việc.
Hậu Quả Và Tác Động Của Content Poisoning Lên AI
Khi một hệ thống AI truy xuất nội dung từ một trang web, nó coi nội dung đó là sự thật. Hệ thống sẽ kết hợp trực tiếp nội dung này vào các bản tóm tắt, đề xuất và quy trình ra quyết định tự động.
Không có xác minh của con người nào xảy ra, và không có cảnh báo nào thông báo cho người dùng về khả năng bị thao túng. Đây là một mối đe dọa mạng mới cần được quan tâm.
Các tác động tiềm tàng rất rộng lớn, bao gồm thao túng thị trường tài chính, thông tin sai lệch chính trị và phá hoại hệ thống tư pháp, đặt ra một mối đe dọa mạng nghiêm trọng cho nhiều lĩnh vực. Khả năng tác động đến các quyết định quan trọng mà không để lại dấu vết rõ ràng làm tăng tính nguy hiểm của kỹ thuật này.
Biện Pháp Phòng Ngừa và Bảo Vệ Hệ Thống AI
Các tổ chức phải triển khai các biện pháp phòng thủ nhiều lớp để bảo vệ hệ thống AI khỏi việc đầu độc nội dung. Việc hiểu rõ mối đe dọa mạng này là bước đầu tiên để xây dựng hệ thống phòng thủ vững chắc và đây là một phần quan trọng của an ninh mạng hiện đại.
Xác Thực Nguồn Gốc (Provenance Validation)
- Tín hiệu nguồn gốc nên trở thành bắt buộc. Yêu cầu các trang web và nhà cung cấp nội dung xác minh mã hóa tính xác thực của thông tin đã xuất bản.
- Điều này giúp thiết lập độ tin cậy và ngăn chặn việc chèn nội dung giả mạo.
Giao Thức Xác Thực Trình Thu Thập Thông Tin (Crawler Validation Protocols)
- Các giao thức phải đảm bảo rằng các user agent khác nhau nhận được nội dung giống hệt nhau. Điều này giúp phát hiện các tấn công mạng cloaking thông qua thử nghiệm tự động.
- Việc kiểm tra tính nhất quán của nội dung là rất quan trọng để phát hiện bất kỳ sự khác biệt nào.
Giám Sát Liên Tục Đầu Ra của AI
- Giám sát liên tục các đầu ra do AI tạo ra là điều cần thiết. Cần gắn cờ những trường hợp kết luận của mô hình khác biệt đáng kể so với các mẫu dự kiến.
- Hệ thống phát hiện xâm nhập có thể được điều chỉnh để tìm kiếm các bất thường này, giúp tăng cường an ninh mạng tổng thể.
Thử Nghiệm Nhận Biết Mô Hình (Model-Aware Testing)
- Thử nghiệm nhận biết mô hình nên là thực hành bảo mật tiêu chuẩn. Các tổ chức cần thường xuyên đánh giá liệu hệ thống AI của họ có hành xử nhất quán khi xử lý cùng một dữ liệu bên ngoài thông qua các phương pháp truy cập khác nhau hay không.
Cơ Chế Xác Minh Trang Web (Website Verification Mechanisms)
- Các cơ chế xác minh trang web phải được tăng cường. Thiết lập các hệ thống danh tiếng để xác định và chặn các nguồn cố gắng lừa dối tác nhân AI trước khi nội dung độc hại được nhập vào.
- Điều này giúp giảm thiểu rủi ro bảo mật từ các nguồn không đáng tin cậy.
Quy Trình Xác Minh Con Người (Human Verification Workflows)
- Các tổ chức sử dụng hệ thống AI cho các quyết định quan trọng phải triển khai quy trình xác minh của con người. Đặc biệt đối với các kết quả có rủi ro cao như tuyển dụng, tuân thủ và xác định mua sắm.
- Con người vẫn là yếu tố then chốt trong việc đảm bảo tính chính xác và an toàn của thông tin, giảm thiểu rủi ro bảo mật từ các hệ thống tự động.
Bài viết liên quan

WARMCOOKIE Nguy Hiểm: Mã Độc Tiến Hóa Đe Dọa An Ninh Mạng

Khẩn cấp: Đánh cắp dữ liệu thẻ tín dụng nghiêm trọng trên WordPress

Nguy hiểm: Mã độc Datzbro chiếm quyền điều khiển thiết bị toàn diện

Lockbit ransomware ESXi: Kỹ thuật evasive nguy hiểm

Microsoft Security Copilot: AI Tối Ưu An Ninh & Quản Lý IT Với Intune, Entra

Seraphic + CrowdStrike: Tăng cường An ninh mạng trình duyệt hiệu quả

VexTrio: Mối Đe Dọa Mạng Toàn Cầu Nghiêm Trọng
